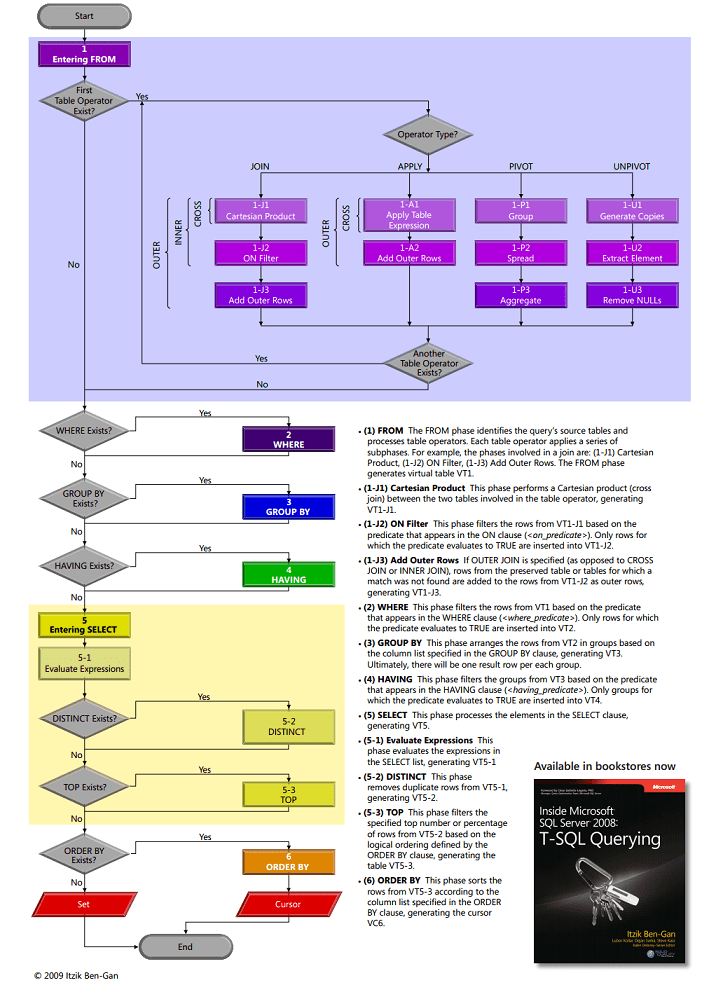
I’ve always found Itzik Ben-Gan’s excellent chart on the logical SQL processing immensely helpful in reasoning about the querying performance. Even though the chart was made for SQL Server, it still is applicable to any database engine that follow SQL Standard, which also includes Access database engine. Though we love using SQL Server databases, we do have occasional Access databases or Access applications that require the use of Access queries (e.g. temporary tables for reporting). Access does not come with fancy-pant profiling tools so what are we to do?
{kind=link}
Jerry-rigging our own trace utility
That got me to wonder — could one determine when a clause of a SQL query get executed and how often? Access does have a mean of showing execution plans but it does not get into the details of how and when the particulars get processed. There is a roundabout way of inferring the physical processing order used by Access database engine: a custom VBA function!
Public Function Trace(EventName As String, Optional Value As Variant) As Boolean
If IsMissing(Value) Then
Debug.Print EventName, "#No Value#"
Else
Debug.Print EventName, Value
End If
Trace = True
End Function
This can be saved in a standard module. We can then set up a simple table:
Tracing the clauses of an Access query
With that set up, we can create an Access query and sprinkle the Trace in different parts of Access query. Here’s one example:
SELECT
c1.ColorID,
Trace("SELECT") AS Ignored1,
Trace("SELECT",c1.Color) AS Ignored2
FROM tblColor AS c1
WHERE Trace("WHERE") <> 0
AND Trace("WHERE", c1.Color) <> 0
ORDER BY
Trace("ORDER BY"),
Trace("ORDER BY", c1.Color);
If you then open the query in datasheet view, then go over to the VBIDE’s immediate window, you should see the output like this:
WHERE #No Value# ORDER BY #No Value# SELECT #No Value# WHERE Red ORDER BY Red WHERE Green ORDER BY Green WHERE Blue ORDER BY Blue SELECT Blue SELECT Green SELECT Red
This provides us with some insights into how Access is resolving the query which can be helpful when you need to optimize a poorly-performing query. Let’s see what we can learn:
- We can see that if there are no column references, the VBA function is called early as possible since Access recognizes that they can only have one value for the entire result set, so there’s no point in calling the function again and again only to get the same answer. You can see that the
Traceinvocations without the 2nd optional argument got evaluated first before all other invocations containing a column reference in the 2nd optional argument. - As a corollary to the previous point, if the invocation contains a column reference, it must be then evaluated at least once for each row. You can see that we go through each color value when evaluating the clause.
- We see that the order is generally similar to what we see in Itzik Ben-Gan’s chart;
WHEREis evaluated as early as possible,ORDER BYis evaluated after we’ve eliminated all non-qualifying rows, then whatever’s left,SELECTis then evaluated. - Though we would expect sorting to be applied after we’ve filtered out non-qualifying rows, it seems that Access prefers to try and sort the output as soon as possible, possibly because it’s cheaper to insert a new row in a sorted list over sorting the whole set.
Additional experiments & conclusions
You can experiment a bit with a different query. For example, you can get an insight into when/often Access processes GROUP BY, by using a query similar to this:
SELECT
c1.ColorID,
Trace("SELECT") AS Ignored1
FROM tblColor AS c1
INNER JOIN tblColor AS c2
ON c1.ColorID = c2.ColorID
WHERE Trace("WHERE") <> 0
AND Trace("WHERE", [c1].[Color]) <> 0
GROUP BY
c1.ColorID,
Trace("GROUP BY", c1.Color)
ORDER BY c1.ColorID;
You can then use this in conjunction with the JetShowPlan to learn more about what the database engine is actually doing. Hopefully, you may find it helpful in gaining insights to how you can improve the performance of your Access query. As a challenge, you could reason about why Access executes the GROUP BY the way it does. I also encourage you to experiment opening a datasheet and scrolling. You will then discover that the SELECT gets re-evaluated as a result of navigating around.
I should point out that the technique above provides us with insight into the physical processing plan, rather than the logical processing order as described in the chart. Accordingly, we should expect the plan to be different for different volume of data or for different query. We also have to consider that adding the Trace function can influence the plan. However, I would argue that if you are so concerned about those considerations, it’s probably better to move that query and its underlying data to a SQL Server database where you have far more options for optimizing the query’s performance.
Have fun!
Need help with Microsoft Access queries? Call Access Experts on (773) 809 5456 or drop the team an email today.