Analyzing the key population query some more
In part 3 of our ODBC tracing series, we are going to take a further insight into Access managing keys for ODBC linked tables and how it sorts and groups the SELECT queries together. In the previous article we learned how a dynaset-type recordset is in fact 2 separate queries with the first query fetching only the keys of the ODBC linked table which is then subsequently used to populate the data. In this article, we will study a bit more about how Access manages the keys and how it infers what is the key to use for an ODBC linked table among with the ramifications it has. We will start with the sorting.
Adding a sort to the query
You saw in the previous article that we started with a simple SELECT without any particular ordering. You also saw how Access first fetched the CityID and use the result of the first query to then populate the subsequent queries to provide the appearance of being fast to the user when opening a large recordset. If you have ever experienced a situation where adding a sort or grouping to a query, thing suddenly slow, this will explain why.
Let’s add a sort on the StateProvinceID in an Access query:
SELECT Cities.* FROM Cities ORDER BY Cities.StateProvinceID;
An Access query with an explicit sorting applied.
Now if we trace the ODBC SQL, we should see the output:
SQLExecDirect: SELECT "Application"."Cities"."CityID" FROM "Application"."Cities" ORDER BY "Application"."Cities"."StateProvinceID" SQLPrepare: SELECT "CityID", "CityName", "StateProvinceID", "Location", "LatestRecordedPopulation", "LastEditedBy", "ValidFrom", "ValidTo" FROM "Application"."Cities" WHERE "CityID" = ? SQLExecute: (GOTO BOOKMARK) SQLPrepare: SELECT "CityID", "CityName", "StateProvinceID", "Location", "LatestRecordedPopulation", "LastEditedBy", "ValidFrom", "ValidTo" FROM "Application"."Cities" WHERE "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? SQLExecute: (MULTI-ROW FETCH) SQLExecute: (MULTI-ROW FETCH)
Traced ODBC SQL for the Access query with a sort.
If you compare with the trace from the previous article, you can see that they are the same except for the first query. Access put the sorting in the first query where it uses to get the keys. That makes sense as by enforcing the sorting on the keys it uses to walk through the records, Access is guaranteed to have a one to one correspondence between a record’s ordinal position and how it should be sorted. It then populates the records exactly the same way. The only difference is the sequence of keys it uses to fill in the other queries.
Let’s consider what happens when we add a GROUP BY by doing a count on the cities per state:
SELECT Cities.StateProvinceID ,Count(Cities.CityID) AS CountOfCityID FROM Cities GROUP BY Cities.StateProvinceID;
An Access query with a GROUP BY predicate.
Tracing should output:
SQLExecDirect:
SELECT
"StateProvinceID"
,COUNT("CityID" )
FROM "Application"."Cities"
GROUP BY "StateProvinceID"
Traced ODBC SQL for the Access query with groupings.
You might have also noticed that the query now opens slowly, and even though it may be set as a dynaset type recordset, Access chose to ignore this and basically treat it as a snapshot type recordset. This makes sense because the query is non-updatable and because you can’t really navigate to an arbitrary position in a query like this. Thus, you must wait until all rows have been fetched before you can freely browse. The StateProvinceID can’t be used to locate a record as there would be several records in the Cities table. Though I used a GROUP BY in this example, it needs not to be a grouping that causes Access to use a snapshot type recordset instead. Using DISTINCT for example would have the same effect. A useful rule of thumb to predict whether Access will use dynaset-type recordset is to ask whether a given row in the resulting recordset maps back to exactly one row in the ODBC data source. If that is not the case, then Access will use snapshot behavior even if the query was supposed to use dynaset.
Consequently, just because the default is a dynaset-type recordset, it does not guarantee that it will be in fact a dynaset-type recordset. It is merely a request, not a demand.
Determining the key to use for selecting
You may have noticed in the previous traced SQL in both this and previous articles, Access used the CityID as the key. That column was fetched in the first query, then used in subsequent prepared queries. But how does Access know which column(s) of a linked table it ought to use? The first inclination would be to say that it checks for a primary key and uses that. However, that would be incorrect. In fact, Access database engine will make use of ODBC’s SQLStatistics function during the linking or re-linking of the table to examine what indices are available. This function will return a resultset with one row for each column participating in an index for all indices. This resultset is always sorted and by convention, it will always sort clustered indices, hashed indices and then other indices types. Within each index type, the indices will be sorted by their names alphabetically. The Access database engine will select the first unique index it finds even if it’s not the actual primary key. To prove this, we will create a silly table with some odd indices:
CREATE TABLE dbo.SillyTable ( ID int CONSTRAINT PK_SillyTable PRIMARY KEY NONCLUSTERED, OtherStuff int CONSTRAINT UQ_SillyTable_OtherStuff UNIQUE CLUSTERED, SomeValue nvarchar(255) );
Transact-SQL to create a silly table with nonclustered primary key and clustered unique indices.
If we then populate the table with some data and link to it in Access and open a datasheet view on the linked table, we will see this in traced ODBC SQL. For brevity, only the first 2 commands are included.
SQLExecDirect: SELECT "dbo"."SillyTable"."OtherStuff" FROM "dbo"."SillyTable" SQLPrepare: SELECT "ID" ,"OtherStuff" ,"SomeValue" FROM "dbo"."SillyTable" WHERE "OtherStuff" = ?
Traced ODBC SQL selecting records from a table with a non-clustered primary key.
Because the OtherStuff participates in a clustered index, it came before the actual primary key and thus was selected by Access database engine to be used in dynaset-type recordset for selecting a individual row. That is also in spite of the fact that the unique clustered index’s name would have come after the primary index’s name. A tactic to force Access database engine to select a particular index for a table would be to alter its type or rename the name so that it sorts alphabetically within the index type’s group. In the case of SQL Server, primary keys are usually clustered, and there can be only one clustered index so it’s a happy accident that it’s usually the correct index for Access database engine to use. However, if the SQL Server database contains tables with nonclustered primary keys and there’s a clustered unique index that may not be the optimal choice. In the cases where there are no clustered indices at all, you can influence which unique indices get used by naming the index so that it sorts before other indices. That can be helpful with other RDBMS software where creating a clustered index for primary key is not practical or possible.
Access-side index for linked SQL view or table with no indices
When linking to a SQL view or a SQL table that does not have any indices or primary key defined, there will be no indices available for Access database engine to use. If you’ve used linked table manager to link a table or a SQL view with no indices, you may have seen a dialog like this:
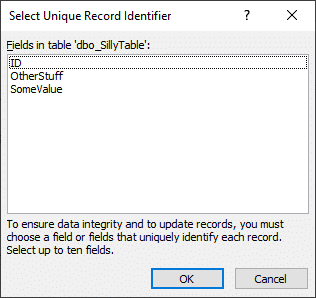
Access dialog shown whenever linking an ODBC table that does not have a primary key, typically with a SQL view.
If we select the ID, complete the linking, open the linked table in design view, and then the indexes dialog, we should see this:
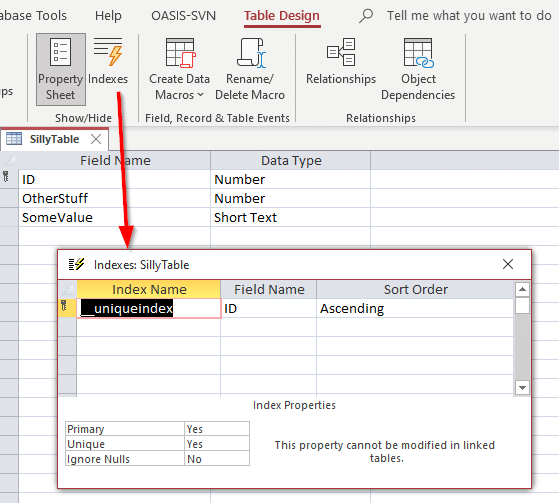
Design view of the ODBC linked table with the Indexes dialog open.
It shows that the table has an index named __uniqueindex but it does not exist in the original data source. What’s going on? The answer is that Access created an Access-side index for its use to help identify which can be used as a record identifier for such tables or views. If you happen to programmtically relink the tables rather than use the Linked Table Manager, you will find it necessary to replicate the behavior in order to make such linked tables updatable. This can be done by executing an Access SQL command:
CREATE UNIQUE INDEX [__uniqueindex] ON SillyTable (ID);
Access SQL command to create a Access-side index on linked table to enable updating on such table.
You can use for instance, CurrentDb.Execute to execute the Access SQL to create the index on the linked table. However, you should not execute it as a pass-through query because the index is not actually created on the server. It is only for Access’ benefits to allow updating on that linked table.
It’s worth noting that Access will only allow exactly one index for such linked table and only if it doesn’t have indices already. Nonetheless, you can see that using a SQL view may be a desirable option for cases where the database design do not allow you to used clustered indices and you do not want to fiddle with index’s name to persuade the Access database engine to use this index, not that index. You can explicitly control the index and the columns it should include when linking the SQL view.
Conclusions
From previous article we saw that a dynaset-type recordset usually issues 2 queries. The first query usually deals wiht populating the We looked more closely at how Access handles the population of keys it will use for a dynaset-type recordset. We saw how Access will actually convert any sorting from the original Access query and then use that in the key population query. We saw that the ordering of the key population query directly impacts how the data in the recordset will be sorted and presented to the user. This enables the user to do things like jumping to an abritrary record based on the ordinal postion of the list.
We then saw that grouping and other SQL operations that prevents one-one mapping between the returned row and the original row will cause Access to treat the Access query as if it was a snapshot-type recordset in spite of requesting a dynaset-type recordset.
We then looked at how Access determines the key to use for managing updates with an ODBC linked table. Contrary to what we might expect, it will not necessarily select the primary key of the table but rather the first unique index it finds, depending on the type of the index and the name of the index. We discussed strategies for ensuring that Access will select the correct unique index. We looked at SQL view which normally do not have any indices and discussed a method for us to inform Access how to key a SQL view or a table that does not have any primary key, allowing us more control over how Access will handle the updates for those ODBC linked tables.
In the next article we will look at how Access actually execute updates on the data when users makes changes via the Access query or recordsource.
Our Access Experts are available to help. Call us on 773-809-5456 or email us at [email protected].