UPDATE: Added some more clarifications around the meaning of SQLExecute and how Access is handling the prepared queries. Thanks, Bob!
What’s Access doing when we browse and look at records in a ODBC linked table?
In the second part of our ODBC tracing series, our focus will turn to the impact the recordset types have within an ODBC linked table. In the last article we learned how to turn on ODBC SQL trace and we can now see the output. If you’ve played with it a bit, you might have noticed that your Access query and the ODBC SQL statements Access generates do not look very similar. We will also provide an in-depth look at how the types influences the behavior of SELECT queries, and we will also look into different variations of recordsets such as Snapshots and Dynasets.
If you want to follow along, you can use the sample database provided here.
Effect of Recordset types in a SELECT query
The recordset types has a big effect on how Access will communicate with the ODBC data sources. You may have noticed that in a form design view or in query design view, you can set the recordset type. By default, it is set to Dynaset.

Recordset types for the Access form.

Recordset types for the Access query.
In VBA, we have few more options but we won’t worry about that for now. Let’s start with understanding what exactly Dynaset and Snapshot means first. We will start with less commonly used type, Snapshot first.
Snapshot type recordsets
Snapshot is quite simple. It basically means we take a snapshot of the result at the time of query’s execution. Normally, this also means Access cannot update the result. However, let’s look at how Access queries the source with a snapshot-based recordset. We can create a new Access query like so:
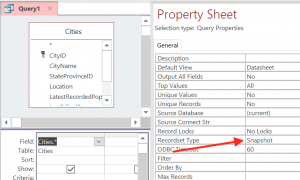
An Access query selecting from a ODBC linked table using snapshot recordset type.
The SQL as we can see in Access query’s SQL view is:
SELECT Cities.* FROM Cities;
Access SQL selecting from a ODBC linked table.
We’ll run the query and then look at the sqlout.txt file. Here’s the output, formatted for readability:
SQLExecDirect: SELECT "CityID" ,"CityName" ,"StateProvinceID" ,"Location" ,"LatestRecordedPopulation" ,"LastEditedBy" ,"ValidFrom" ,"ValidTo" FROM "Application"."Cities"
Traced ODBC SQL for opening a query in datasheet view.
There were few differences between what we wrote in Access’ query compared to what Access sent to ODBC, which we will analyze.
- Access qualified the table with the schema name. Obviously, in Access SQL dialect, that does not work the same way but for ODBC SQL dialect, it’s helpful to ensure that we are selecting from right table. That is governed by the
SourceTableNameproperty. - Access expanded the contents of
Cities.*into an enumerated list of all columns that Access already knows about based on theFieldscollection of the underlyingTableDefobject. - Access used the
"to quote the identifiers, which is what ODBC SQL dialect expects. Even though both Access SQL and Transact-SQL uses brackets to quote an identifier, that is not a legal syntax in the ODBC SQL dialect.
So even though we only did a simple snapshot query selecting all columns for a table, you can see that Access does lot of transformation to the SQL between what you put in the Access query design view or SQL view versus what Access actually emits to the data source. In this case, however, it’s mostly syntactic so there is no real difference in the SQL statement between the original Access query and the ODBC SQL statement.
The trace also added SQLExecDirect at start of the SQL statement. We’ll circle back to that once we’ve looked at few other examples.
Dynaset type recordsets
We’ll use the same query but change the property back to its default, Dynaset.
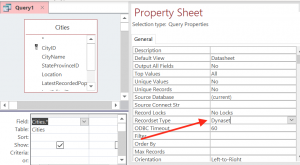
Access query, modified to use dynaset as the recordset type.
Run it again, and we will see what we get from the sqlout.txt. Again, it’s formatted for readability:
SQLExecDirect: SELECT "Application"."Cities"."CityID" FROM "Application"."Cities" SQLPrepare: SELECT "CityID" ,"CityName" ,"StateProvinceID" ,"Location" ,"LatestRecordedPopulation" ,"LastEditedBy" ,"ValidFrom" ,"ValidTo" FROM "Application"."Cities" WHERE "CityID" = ? SQLExecute: (GOTO BOOKMARK) SQLPrepare: SELECT "CityID" ,"CityName" ,"StateProvinceID" ,"Location" ,"LatestRecordedPopulation" ,"LastEditedBy" ,"ValidFrom" ,"ValidTo" FROM "Application"."Cities" WHERE "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? SQLExecute: (MULTI-ROW FETCH) SQLExecute: (MULTI-ROW FETCH)
Traced ODBC SQL from a dynaset-type recordset.
Wow, lot of things happening! This is definitely more chatty than the snapshot-type recordset. Let’s go over them one by one.
The first one only selects the CityID column. That happens to be the primary key of the table, but more importantly, that’s the index that Access is using on its side. That will become important when we study views later. Access uses this query to get the keys and use that to fill in other queries later as we’ll see.
The second statement is more closer to the original snapshot query, except we now have a new WHERE clause filtering on the CityID column. From that we can see that it’s a single-row fetch. We can use the keys we got from the first query and collect the rest of columns in this query. Whenever that prepared statement gets executed, you will see a SQLExecute: (GOTO BOOKMARK).
But that would be inefficient if we had to do this for all rows… And that’s where the next query comes in. The 3rd statement is similar to the 2nd but has 10 predicates. This prepared query gets executed with each SQLExecute: (MULTI_ROW FETCH). So what this means is that when we load a form or a datasheet or even open a recordset in VBA code, Access will use either the single-row version or multiple-row version and fill in the parameters using the keys it got from the first query.
Background fetching and resynchronizing
Incidentally, have you ever noticed how when you open a form or a datasheet, you don’t get to see the “X of Y” in the navigation bar?
Navigation bar showing only the ordinal position.
That’s because Access cannot know how many there are until it has finished collecting the results from the first query. That is why you may often find that it’s very fast to open a query that returns large amount of data. You are only previewing only a small window of the entire recordset while Access is fetching the rows in background. If you click on the “Go To Last” button, you might then find that it freezes up Access. You would have to wait until it has finished fetching all the keys in the first query before we can see the “X of Y” in the navigation bar.
Navigation bar showing both the oridinal position and total count of the recordset’s records.
Thus, you can appreciate how Access can provide the illusion of being quick to open even a large recordset when we use a dynaset type recordset and that is usually a good experience for user.
Finally, we need to note that we got 3 different types of executions, SQLExecDirect, SQLPrepare and SQLExecute. You can see that with the former, we do not have any parameters. The query is simply as-is. However, if a query needs to be parameterized, it has to be first prepared via SQLPrepare and then later executed with SQLExecute with values for parameters provided. We cannot see what values was actually passed into the SQLExecute statement though we can infer from what we see in Access. You can only know whether it fetched a single row (using SQLExecute: (GOTO BOOKMARK) or multiple rows (using SQLExecute: (MULTI-ROW FETCH)). Access will use the multiple-row version to do background fetch and fill the recordset incrementally but use the single-row version to fill only one row. That might be the case on a single form view as opposed to continuous form or datasheet view or use it for resynchronizing after an update.
Navigating around
With a large enough recordset, Access might not be able to ever finish fetching all the records. As noted previously, the user is presented with the data as soon as possible. Normally, when the user navigates forward through the recordset, Access will keep fetching more and more records to keep the buffer ahead of the user.
But suppose that the user jumps to 100th row by going to navigation control and entering 100 there?
![]()
Jumping to 100th record by entering “100” in the navigation bar.
In that case, Access will submit the following queries…
SQLExecute: (MULTI-ROW FETCH) SQLExecute: (GOTO BOOKMARK) SQLExecute: (MULTI-ROW FETCH) SQLExecute: (MULTI-ROW FETCH)
Traced ODBC SQL from a dynaset-type recordset when user jumps to an arbitrary position.
Note how Access uses the already prepared statements it created at the time of opening the recordset. Because it already has the keys from the first query, it is able to know which is the “100th” row. To use a more concrete example. Suppose that we had CityID starting at 1, 3, 4, 5…99, 100, 101, 102 with no record for the CityID = 2. In the first query, the CityID 101 would be in 100th row. Therefore, when user jumps to 100, Access looks up the 100th row in first query, see that it’s CityID 101, then takes that value and feeds that into the SQLExecute: (GOTO BOOKMARK) to immediately navigate to that record. It then looks at the next 10 records and use those subsequent CityID to fill the buffer with multiple SQLExecute: (MULTI-ROW FETCH). You may have noticed that there is a multiple rows fetch before a single row fetch. Access is actually fetching the 101th-110th rows in the multiple rows fetch and fetches the 100th record in the next single row fetch.
Once Access has gotten the data for the rows at 100th It takes the user there, then start filling up the buffer around that 100th row. That enables the user to view the 100th row without having to wait to load all of the 11th-99th records. The user also has apparently quick browsing experience when the user clicks previous or next from the new position because Access already loaded it in the background before the user asked for it. That helps gives the illusion of being fast even over a slow network.
But even if the user left the form open and idle, Access would continue to perform both background fetch and refresh the buffer to avoid showing the user stale data. That is governed by the ODBC settings in Options dialog, under the Advanced section in the Client Setting tab:
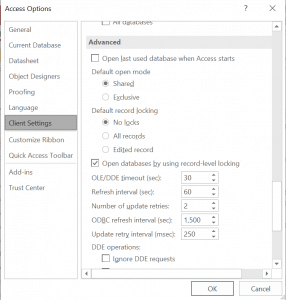
Options dialog showing options relevant to ODBC background fetch.
The default for ODBC refresh interval is 1500 seconds but can be changed. It also can be changed via VBA.
Conclusions: Chunky or Chatty
You now should see that the main reason why dynaset-type recordsets are updatable but snapshot-type recordsets are not is because Access is able to substitute a row in the recordset with newest version of the same from the server since it knows how to select a single row. For that reason, Access needs to manage 2 ODBC queries; one to fetch the keys and other to fetch the actual contents of rows for a given key. That information was not present with a snapshot type recordset. We just got a big blob of data.
We looked at 2 major types of recordsets though there are more. However, others are just variants of the 2 types we covered. But for now, it suffices to remember that to use snapshot is to be chunky in our network communication. On the other hand, to use dynaset means we will be chatty. Both have their ups and downs.
For example, snapshot recordset needs no further communication with the server once it has retrieved the data. As long the recordset stays open, Access can freely navigate around its local cache. Access also does not need to keep any locks and thus block other users. However, a snapshot recordset is by necessity slower to open since it has to collect all the data upfront. It can be a poor fit for a large recordset, even if you intend to read all the data.
Suppose that you are creating a large Access report that’s 100 pages, it’s usually worthwhile using dynaset-type recordset. It can start rendering the preview as soon as it has enough to render the first page. That is better than forcing you to wait until it has retrieved all the data before it can start rendering the preview. Though a dynaset recordset may take locks, it usually is for brief time. It is only long enough for Access to resynchronize its local cache.
But when we think about how many more requests Access submits over the network with a dynaset-type recordset, it’s easy to see that if the network latency is poor, Access’ performance will suffer accordingly. In order for Access to allow users to edit and update data sources in a generic manner does require that Access keep track of keys for selecting and modifying a single row. We will look at this in the upcoming articles. In the next article, we will look at how sorting and groups affects a dynaset-type recordset as well how Access determines the key to use for a dynaset-type recordset.
For more help with Microsoft Access, call our experts on 773-809-5456 or email us on [email protected].
Thank you!
Great, thanks for your feedback. I’ve updated the article to help make this more clear. Much appreciated!
I do not understand the queries submitted for the section ” suppose that the user jumps to 100th row”.
Could you explain further, especially:
What does this do: SQLExecute: (GOTO BOOKMARK)
How do the queries provide downloading of data prior to record 100
Overall this is a GREAT series. Thank you!
Bob Alston
Thank you for the questions, Bob!
If you look at the screenshot titled “Jumping to 100th record by entering “100” in the navigation bar.”, you can see that the user can type in 100 (or any number) in the navigation bar to jump to an arbitrary position. In VBA, we can do the equivalent with code using Move method like this:
Set rs = CurrentDb.OpenRecordSet(...)rs.Move Rows:=100
In this case, Access will look up what’s the 100th record from the key population query and then feed that into both prepared statements. It first uses the prepared statement with a single
WHEREpredicate to fetch that 100th record. That is shown asSQLExecute: (GOTO BOOKMARK)which indicates that it did a single-row fetch. TheSQLExecute: (MULTI-ROW FETCH)means that the prepared statement with 10WHEREpredicates is used to fetch 10 more rows, usually the 101th-110th records to fill in the buffer. As I mentioned earlier, ODBC tracing unfortunately does not report what parameter values it actually feeds. However, you can run the ODBC SQL and infer what would be parameters from the key population query. As an example, let’s say we have a table that has aCityID. If we open the table and suppose there are IDs valued at 1, 3, 4, 5, 6 … 97, 98, 99, 100, 101. Without any explicit sorting, theCityID101 would be the 100th record in the key population query. Access will then take the101and then feed it into the prepared statement so it’s nowWHERE "CityID" = 101. For the multiple-rows prepared statement, it would beWHERE "CityID" = 102 OR "CityID" = 103 OR "CityID" = 104 .... OR "CityID" = 111.That’s how Access can bypass the need to download the entire rows from the
Citiestable whenever user jumps to a random position. The key population query provides that information, which is also why I showed that the sorting changes how the key population query is executed. Whatever order the keys comes in that query then becomes the ordinal position that Access uses on the form / recordset for navigation.I hope that helps? Let me know and I’ll expand accordingly!